This chart only goes back a bit, but I'm down 27 pounds since April.
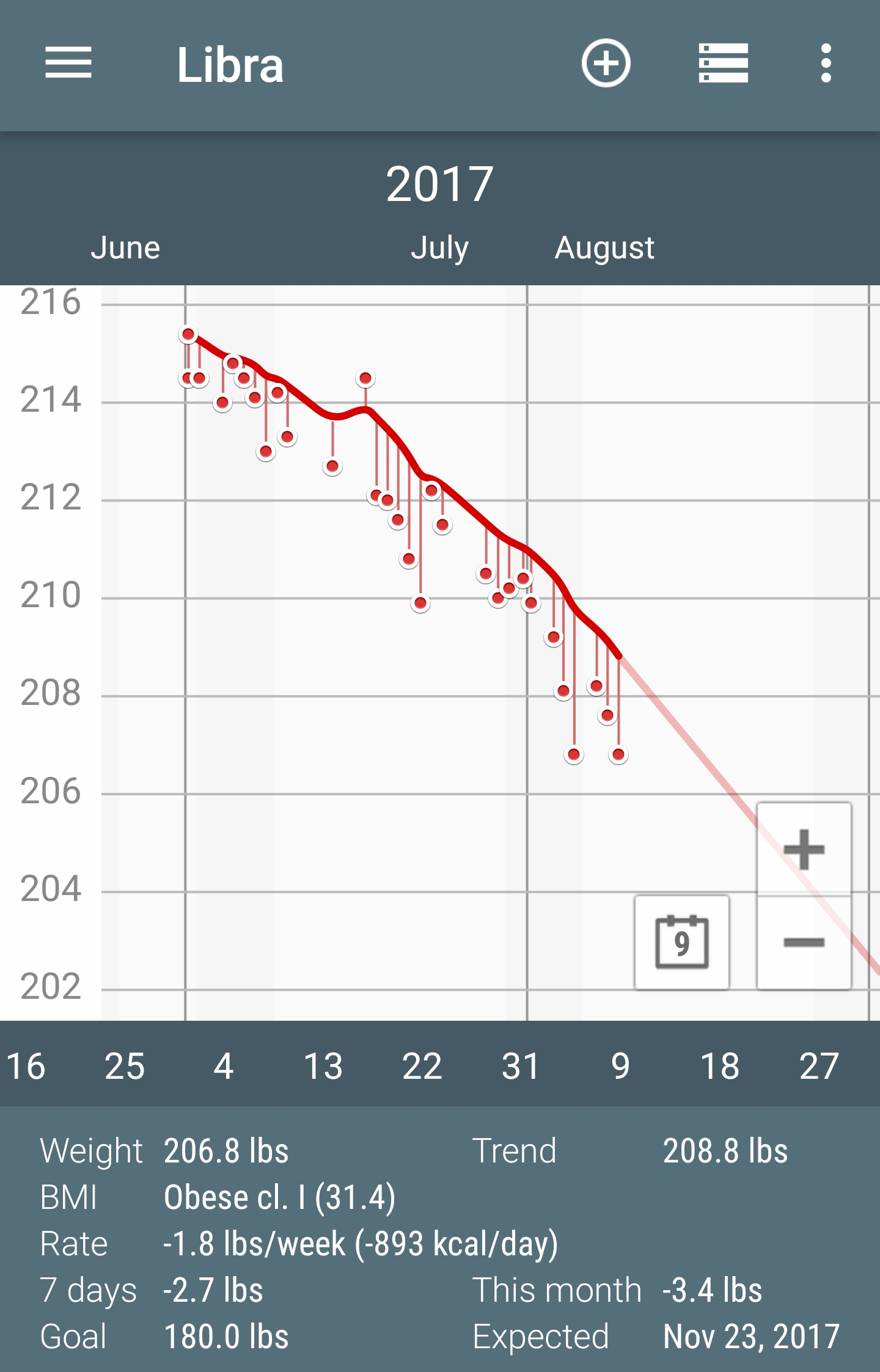
This chart only goes back a bit, but I'm down 27 pounds since April.
My wife and son will be spending the night camping outside. I'd love to join them, but someone has to stay inside and have the entire bed to himself.
this is a test post for testing wpghs.
this is a test post for testing wpghs.
this is a test post for testing wpghs.
This weekend, I was finally clearing out the bit of walk between my pole barn and the hill behind it. Erosion has been filling it in, making it hard to get back there with any sort of push mower. Vines and brush have been filling in around it. I did what I could with the trimmer, then I went back in with the machete. Now, this machete was $6 at Harbor Freight and I haven't used it much because the cheap plastic handle was starting to break.

I didn't get a before photo, but one can see the kind of brush I was dealing with slightly up the hill. It wasn't long before the handle was completely apart. The blade was fine, but the only thing holding the handle on the blade was.. my hand. I eventually ditched the handle, wrapped the base with 550 cord, and was able to finish, though my rope handle too started to unravel.
Last night I considered that today I would run up to Harbor Freight and pick up another cheap machete. They're $6 and I don't use them that often. But I would really like to be sure that the machete gets through a full job. There's also this adage concerning tools: Buy the cheap one first and if you use it enough to wear it out, then buy a more expensive one. I went and looked on amazon, and they started off around $14. One these, I saw some reviews about the blades bending right away or rusting. Well.. this started me on a pretty dangerous journey to find the best machete to buy.
My first step on this journey was a pair of articles on bushcraftpro.com,
one focused on clearing brush and another on chopping wood. Both are written by the same author, and follow a similar format (buying a better machete for the husband to use). They certainly opened my eyes to the much larger world of machetes. The machetes that I'm used to seeing with a blade and saw on the back are common, but are never in the top of the list. A number of people prefer machetes over hatchets for chopping wood. There's a youtube video showing propper chopping technique. I also learned that "the best" machete you can get is probably anything by Condor Tool & Knife. From their line, expect to pay around $50 to $90. This was a far cry from $14. I said "that's too much, and this article is bunk" and started looking for other opinions. I was awoken to the idea that instead of the hatchet I keep in my car, I might want a machete instead.
I came across survival prep forums. People making their machete pick based on the impending collapse of society and/or the zombie apocalypse. I learned that machetes are "old hat" and I should consider Malaysian Parangs or Nepalese Kukris instead. I found the woodmans pal, which looks amazing and has stories off WW2 servicemen using them against enemies with katanas. I discovered Gerber used to make a good machete, but then they lowered the quality, so now it sucks.
After all this research, I went to bed thinking of what kind of awesome machete, Parang, or Kukri I would buy. Something I could keep in the car for brush clearing emergencies, perhaps with a sheath I could hook to my belt. Something I could use while camping or clearing out more brush from around the buildings. I had machete fever.
This morning, I woke with a slightly clearer head. I've used a machete about twice in the last 6 years. I've only once encountered a fallen tree on the road once that I can recall. In that case, I had no tools to clear it with, but was able to edge the car around it and leave the problem for the next unfortunate traveler. I keep thinking I'd like to go camping, but I haven't done that in 20 years. I doubt buying a $80 knife would change that. If anyone learned how much I paid for my expensive knife, they would ridicule me and rightly so after a couple months, I would have forgotten all the details as to why this was so incredible and not be able to justify it other than 'better handle'.
This has been about machetes, but it's really a dangerous issue with learning too much. You start looking for something a little better. Then you learn that the one simple tool you never really thought about has an entire world of clashing opinions around it, and suddenly you start identifying with people who (claim to) use that tool for things that you never actually do.
So what blade am I planning to get? I'm not sure yet, but I do have it narrowed down.
This morning I took a meter I was working on outside so I could take it apart and watch my son run around the yard. I planned ahead and took a box to hold the parts. After I had gotten a couple screws out, the wind picked up and blew my box into the yard. I can't find the funny screws in the grass. I should have left them out of the box.
Here's a quick summary of changes that have taken place:
Over the course of this last week (really a good bit of this year) I've been doing a lot more web work. In February, I launched Nifty Noodle People, an event website to promote BCARS's rebranded Skills Night 2.0. After trying many, many different systems, I settled on WordPress. WordPress is something I moved away from back in 2012. However, for a single purpose site, WordPress really impressed me. It impressed me so much, that I decided that I should redo BCARS site under wordpress as well. I had been using Mezzanine, Django-based CMS to manage their site and mine. But Mezzanine has been showing its age and often causing more problems than it's worth when it comes to doing updates or adding things like an event calendar.
I setup a BCARS development wordpress site and started importing content into it. I spent a lot of time looking at different calendars. For Nifty Noodles, I had used The Events Calendar, and it's a really nice calendaring system. But when I was trying to utilize it for BCARS, I ended up not liking the formatting options. I went back into research mode and ultimately settled on time.ly. I even picked up their Core+ package which lets me re-use vendors and organizers. This let me add in recurring events like meetings and weekly nets, and it allows people viewing the site to filter between regular and featured events (like a VE session).
As I was secretly working on this, it was brought up at a club meeting that the club would like to see a way to buy and sell gear on the site. So I added bbPress forum to the development site. Then I launched it silently on April 24th. It has gotten pretty solid reviews from people visiting it.
As I was doing all this work, I observed that my Dreamhost VPS was prone to crashing. I also made an alarming discovery that I was paying a lot more each year than I had remembered. Also, I often get issues with it running out of memory and getting rebooted. I decided it was time to go searching. I had stuck with Dreamhost because of their nice control panel. They made it easy to spin up new sites, sub-domains, and "unlimited" everything. But it's time to move on.
I looked at web hosts, then I looked at plain VPSes. I discovered that OVH had some really good pricing on SSD VPSes. A couple years ago, I would have bulked at "wasting time" managing a server in order to do something simple like pushing web content. But my skills with config management have come a long way over the last 5 years. I decided I would use Ansible to manage the VPS and use all the myriad of roles out there to do so. I'll hopefully write more on that later. But in short, I've got roles installing mongodb, mysql, nginx, letsencrypt, and managing users. I couldn't find a suitable role to manage nginx vhosts, especially in a way to start with a vhost on port 80, and not clobber the information letsencrypt puts in when it acquires a certificate. I hope to make a role that maintains http and https config separately, only putting in the https configuration if the certificate files exist.
But I digress.
During all this, I have been giving lots of thought to moving YourTech to wordpress as well. It's a bit more challenging because I write all my notes in Markdown, which I then convert into posts. I started markdown blogging in 2012, and have shifted platforms several times since, most recently on Mezzanine. I was also thinking of better ways to engage the audiences of YourTech, BCARS, and Nifty Noodles. I had come across this article about replacing Disqus (which I had used) with Github comments. While I liked the idea, I knew it wouldn't work for my goals. I kept coming back to forum software. I found three modern variations Discourse, NodeBB, and Flarum. Of the three, I like Flarum the best. Unfortunately, Flarum is still under heavy development and not recommended for production use. The authors can't yet guarantee that you'll be able to preserve data through upgrades. They want the flexibility to make changes to the database structure as they develop features. So I went to the next best, which is NodeBB.
NodeBB has a blog comments plugin that allows you to use a NodeBB to handle comments on your blog. The pieces all started coming together. I installed NodebB on my VPS as https://community.yourtech.us/. I changed the links on BCARS forums to point to this new community site, and integrated comments for BCARS.
This weekend, I decided to pull the plug on YourTech.us and migrate it simultaneously into wordpress and into the new server. I new this would cause downtime, but since my blog is not commercian, and not exactly in the Alexa Top 500, I wasn't too concerned. If anyone did notice downtime between the 5th and 7th, let me know below.
The move was not without hitches. I did have a markdown copy of all my posts, but I had to add yaml frontmatter to the top of them for github wordpress sync to work. Then I discovered that the plugin ignores my post_date and just makes all my posts match the time of the sync. Also, using the same repository I had been using in development caused issues as well. But eventually, I got all my posts imported with their original post date.
What I didn't import was my resume and personal history. My contact page I did import, but it is rather out of date, so I feel I should update it soon. I want to rethink what I have on all three pages and how I present them, so that's a future project.
Finally, I discarded the handful of disqus comments I had and integrated the comment system with YourTech Community.
UPDATE: Content has been re-added, but the published date information is still being corrected.
I am migrating the site to a new server and from mezzanine to wordpress.
There's always a few thins to work out, and I should be able to restore the content sometime this weekend.
I've been incrementally updating my home lab, and now I really wish I had a 3D printer. These cable combs look like they would be awesome for when it comes to getting the server rack re-organized.
http://www.thingiverse.com/thing:1320948/
One commenter said that the ones with a zip-tie slot will also fit nicely into a rack's square hole. I do have a 3D printer on my "big ticket wish list" but I don't think it's in the cards for this year.


