The two key components:
- Ceph OSDs: A Ceph OSD Daemon (Ceph OSD) stores data, handles data replication, recovery, backfilling, rebalancing, and provides some monitoring information to Ceph Monitors by checking other Ceph OSD Daemons for a heartbeat. A Ceph Storage Cluster requires at least two Ceph OSD Daemons to achieve an active + clean state when the cluster makes two copies of your data (Ceph makes 3 copies by default, but you can adjust it).
- Monitors: A Ceph Monitor maintains maps of the cluster state, including the monitor map, the OSD map, the Placement Group (PG) map, and the CRUSH map. Ceph maintains a history (called an “epoch”) of each state change in the Ceph Monitors, Ceph OSD Daemons, and PGs. Ceph uses the Paxos algorithm, which requires a consensus among the majority of monitors in a quorum. With Paxos, the monitors cannot determine a majority for establishing a quorum with only two monitors. A majority of monitors must be counted as such: 1:1, 2:3, 3:4, 3:5, 4:6, etc. Side note: some ceph docs advise not to comingle Montior and Ceph OSD daemons on the same host or you may encounter performance issues. But in deployment guides and the Mellanox high performance paper, they do comingle them. For all test purposes, I plan to comingle them (deploy monitor on ecs nodes) and evaluate performance under load. I am also still trying to estimate how many monitors per Ceph OSD. We'll have 480 Ceph OSDs per rack, and we'll want either 3, 5, or 7 monitors. I'm going to take a shot in the dark and go with 5.
- RADOS GW This is what provides the S3 and SWIFT API access to Ceph file storage. You can install this on the OSD nodes (simplest) or select a handful of external VMs to run these. You would setup multiple RADOS GW nodes, and place a load balancer like haproxy or nginx/lua_proxy in front of them.
OSD Notes:
OSD Journal Location: stores a daemon's journal by default on /var/lib/ceph/osd/$cluster-$id/journal - on a ECS node, this would be an SSD, which is recommended by CEPH. However, you could point it to an SSD partition instead of a file for even faster performance.
OSD Journal Size: The expected throughput number should include the expected disk throughput (i.e., sustained data transfer rate), and network throughput. For example, a 7200 RPM disk will likely have approximately 100 MB/s. Taking the min() of the disk and network throughput should provide a reasonable expected throughput. Some users just start off with a 10GB journal size. For example:
osd journal size = 10000
OSD's can be removed gracefully: http://docs.ceph.com/docs/master/rados/operations/add-or-rm-osds/#removing-osds-manual
Check Max Threadcount: If you have a node with a lot of OSDs, you may be hitting the default maximum number of threads (e.g., usually 32k), especially during recovery. You can increase the number of threads using sysctl to see if increasing the maximum number of threads to the maximum possible number of threads allowed (i.e., 4194303) will help. For example:
sysctl -w kernel.pid_max=4194303
Crush MAP
The "location" of each Ceph OSD is maintained in a CRUSH MAP.
The CRUSH algorithm determines how to store and retrieve data by computing data storage locations. CRUSH empowers Ceph clients to communicate with OSDs directly rather than through a centralized server or broker. With an algorithmically determined method of storing and retrieving data, Ceph avoids a single point of failure, a performance bottleneck, and a physical limit to its scalability.
CRUSH maps contain a list of OSDs, a list of ‘buckets’ for aggregating the devices into physical locations, and a list of rules that tell CRUSH how it should replicate data in a Ceph cluster’s pools. By reflecting the underlying physical organization of the installation, CRUSH can model—and thereby address—potential sources of correlated device failures. Typical sources include physical proximity, a shared power source, and a shared network. By encoding this information into the cluster map, CRUSH placement policies can separate object replicas across different failure domains while still maintaining the desired distribution. For example, to address the possibility of concurrent failures, it may be desirable to ensure that data replicas are on devices using different shelves, racks, power supplies, controllers, and/or physical locations.
The short of this is that in ceph.conf, you can define a host's location, which subsequently defines the location of each Ceph OSD operating on that host. A location is a collection of key pairs consisting of Ceph predefined types.
root=default row=a rack=a2 chassis=a2a host=a2a1
# types (from narrowest ascending to broadest grouping)
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 region
type 10 root
Each CRUSH type has a value. The higher this value, the less specific the grouping is. So when deciding where to place data chunks or replicants of an object, Ceph OSDs will consult the crush maps to find other Ceph OSDs in other host, chassis, and racks. The fault domain policies can be defined and tweaked.
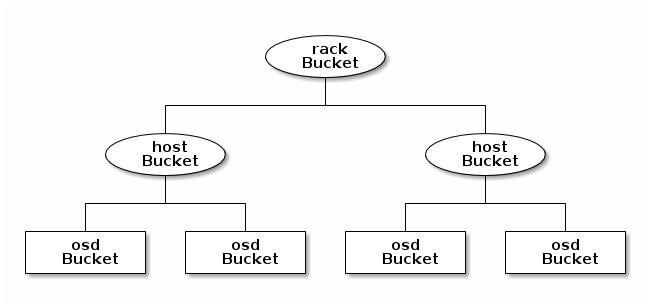
https://www.mellanox.com/related-docs/whitepapers/WP_Deploying_Ceph_over_High_Performance_Networks.pdf - High performance ceph builds.
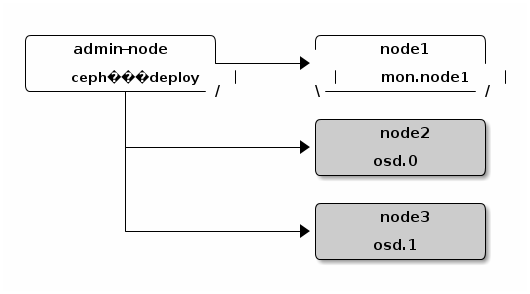
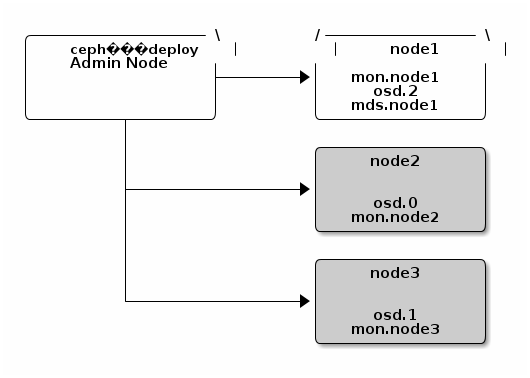

 ](https://lh3.googleusercontent.com/--RicSliZ2kE/VDb9oB4auGI/AAAAAAAAT1M/eCkTaa8AIEg/w876-h1168-no/14%2B-%2B1 target="_new").
](https://lh3.googleusercontent.com/--RicSliZ2kE/VDb9oB4auGI/AAAAAAAAT1M/eCkTaa8AIEg/w876-h1168-no/14%2B-%2B1 target="_new").{kind=link}